Machine Learning, Artificial Intelligence, Neural Networks — these words have become a part of our day-to-day lexicon over the last few years. Scientists throughout India have started employing machine learning techniques in fields as diverse as biomedical diagnostics and wildlife conservation. In this article, we explore the critical question — Why now? Why has the machine learning boom waited until this last decade to come into its own?

In recent times, we have seen an increasing number of instances of Artificial Intelligence (AI) donning the proverbial lab coat. In early 2019, thousands of people were screened every day in a hospital in Madurai by an AI system developed by Google that helps diagnose diabetic retinopathy, a condition that can lead to blindness. Startups like Niramai, based in Bengaluru are developing AI technology for early diagnosis of conditions like breast cancer and river blindness.
The sudden, accelerated growth of Machine Learning not just in research but in all walks of life can bring to mind Black Mirror-esque visions of dystopia in which machines rule over humanity. But let us leave worrying about the consequences of the far future to science fiction and look at the immediate impact this technology has had in science.
The terms Artificial Intelligence and Machine Learning are often used interchangeably, but there is a slight distinction. AI can be used to describe any machine capable of performing tasks we consider requiring intelligence, such as playing chess.
Back in 1997, IBM’s Deep Blue computer forced its way through over 200 million computations per move to defeat the reigning chess world champion, Gary Kasparov. This event created similar wild predictions of global machine dominance. However, Deep Blue was an early supercomputer with less processing power than the smartphone in your pocket today. While Deep Blue was completely programmed by humans, it could very well be called an artificial intelligence. However, it involved no aspect of Machine Learning.
Machine Learning provides computers with the ability to develop ways of solving problems without being programmed to do so. Machine learning algorithms are designed to identify patterns and make decisions the way humans do. This simple shift in programming from instruction to learning has led to some remarkable results. However, the question worth investigating is, why now? Why has this particular decade led to the evolution and proliferation of such powerful algorithms?
In order to find an answer, I spoke with Sudhakaran Prabakaran, a lecturer at the Department of Genetics at the University of Cambridge, as well as an Assistant Professor at the Indian Institute of Science Education and Research (IISER), Pune. My first hunch was that the growth of AI in research today could perhaps be attributed to recent developments in their algorithms. Consider the following excerpt written in Spanish, that can be expertly translated by a machine:
Hoy en día los algoritmos de inteligencia artificial son extremadamente sofisticados y son utilizados en todas partes. Probablemente está leyendo una traducción en inglés de este párrafo dado por el traductor de Google. En el 2016, el traductor de Google cambió todo su código a un sistema de traducción automática neuronal — un cambio que ha reducido el tamaño de su interfaz de cienes de miles de líneas de código a solo 500. Sin duda este cambio ha dado mejores resultados comparado con las frases extrañas dadas antes.
Translation by Google translate:
Today, artificial intelligence algorithms are extremely sophisticated and are used everywhere. You are probably reading an English translation of this paragraph given by the Google translator. In 2016, the Google translator changed all its code to a neural machine translation system — a change that has reduced the size of its interface from hundreds of thousands of lines of code to just 500. No doubt this change has given better results compared to the strange phrases given before.
Despite their present-day success, it turns out that the inception of machine learning algorithms goes far, far back in the past. Prabakaran notes that the very first machine learning algorithms were designed as early as the 1950s. These were called neural networks since they mimicked the way neurons are interconnected in our brain.
A neural network is given a set of information as input such as a phrase in Spanish and is expected to predict an outcome like an English translation of the phrase. ‘Learning’ proceeds by a process similar to trial-and-error, except that each try is influenced by feedback from the previous tries. The network tests its performance against the expected set of results and retries the prediction with slightly modified internal settings. This process is repeated until the network finds the seemingly magical configuration that gives the right answer almost every single time.
Today’s machine learning algorithms come in many more different avatars compared to basic neural networks, but their underlying principles remain the same. These algorithms have very interesting names, like convolutional neural networks, genetic programming, random forests, lasso and so on. Yet the frameworks for even these advanced algorithms were already established well before the turn of the millennium.
Why then was it uncommon to see them being implemented in scientific research? Did we lack relevant research questions to apply these techniques to?
Not quite.
Prabakaran gives the example of a very early problem-solving technique that was used in London way back in 1854. The city was facing a deadly cholera epidemic, the cause of which was unknown at that time. In an effort to control it, several scientists were studying the outbreak closely to figure out where it started and how it spread.
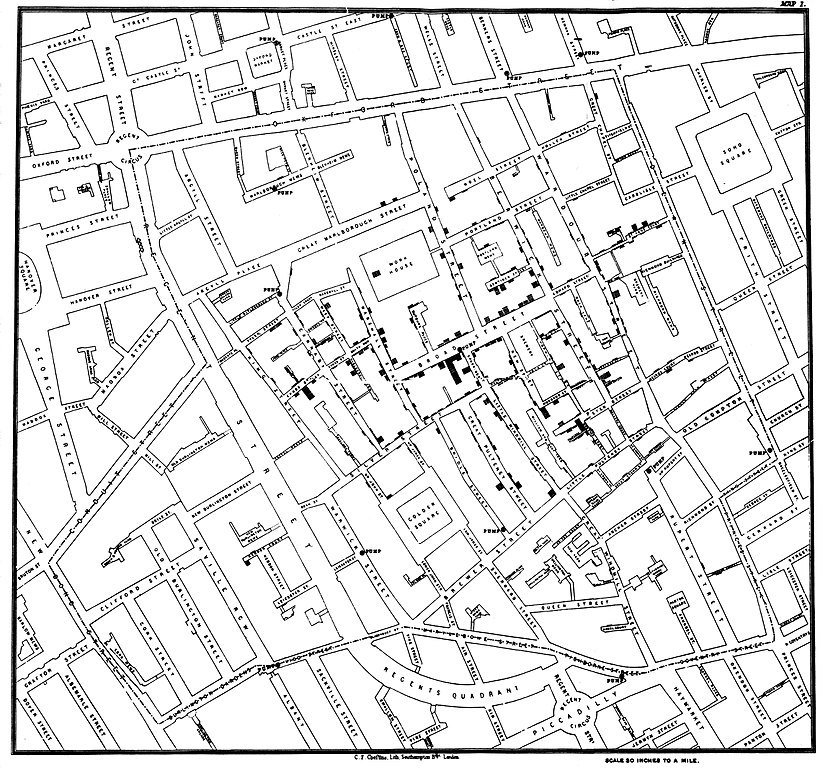
The breakthrough was made by a physician named John Snow, who drew a detailed map of the Soho district in London showing places where individual cases of cholera were recorded. Far from knowing nothing, this John Snow soon arrived at the big picture by meticulously arranging all available information. He realized that most cholera cases were clustered around certain water pumps. This led him to correctly correlate the disease to contaminated water supplied by these particular pumps.
What John Snow did is exactly what AI is so good at — clustering information and finding patterns. There have always been research questions which required effective use of these techniques. What John Snow and the early pioneers of AI did not have access to, was fast and efficient computers. Is that what lead to the AI revolution?
Yes, but that is only part of the answer.
The advent of the silicon age in the 80s and the 90s made faster, cheaper and smaller computers available to everyone. The steep growth in processing power helped create leaps of progress with the use of statistical data analysis techniques and automation in scientific research. Yet, for a long time, the AI algorithms remained relatively in the shadow.
To complete the answer, notice that we have been gradually uncovering more and more information in order to find out what makes machine learning effective today. This is exactly what makes machine learning algorithms flourish! We need data, and in immense quantities.
“The datasets needed to train and test machine learning algorithms today are not produced by a single individual, lab or institution, but by entire consortiums,” explains Prabakaran. His group is involved with The Cancer Genome Atlas (TCGA) consortium, which has accumulated over 5 Petabytes of data about many different kinds of cancer — an amount of data so humongous that if we were to write it all on CDs and stack them vertically, it would reach the height of Mt. Everest!
According to Prabakaran, the biological sciences witnessed several inflection points when it came to gathering quantitative data. An important one came with the completion of the Human Genome project at the turn of the millennium. Starting in 1990, it took 13 years to complete sequencing the first human genome. 15 years hence, the number of genomes sequenced is now approaching 1 million.
It’s not just limited to genomic sequences. Consortiums worldwide are collecting data at a rapid rate and on stupendous scales. This includes structural information about proteins and other cell components, microscopic images of cells and tissues, MRI scans, satellite images of vegetation and oceans to name a few. It is estimated that the total size of biological datasets is now of the order of exabytes, which would make the height of our stack of CDs reach a satellite’s orbit.

Beyond refinements in the techniques involved in collecting data, we can also store and manœuvre it like never before. Cloud computing is proving to be the key to enable numerous researchers across the globe access to analyse a common pool of data. This is instrumental in forging collaboration between different labs and institutions. Increased collaboration, especially with industry, has helped bring down costs. While the Human Genome Project cost a total of almost $3 billion, you can walk into a clinic today and get a scan of your genomic data for less than $1000.
Finally, it is the availability of open-source software for machine learning with a relatively gentle learning curve that really makes it possible for any individual to use them to draw some fantastic inferences from their data. “Even with relatively less computing experience, one can learn machine-learning modules based in programming languages like R and Python within months,” says Prabakaran.
All of this has made it easy for researchers from a diverse pool of backgrounds — from experimental biologists to physicists and mathematicians to wear the hat of a data scientist using machine learning for their work. Examples include a November 2018 study from the Karnataka Forest Department in which AI helped perform a comprehensive survey of leopards in South India. In July 2019, researchers from the United States in collaboration with the Centre for Wildlife Studies, Thrissur, Kerala used Machine Learning to identify bat species which could potentially cause an outbreak of the Nipah virus.
Even if we just look at the last two years, the list of AI applications that have changed our perspectives towards the stories our gathered data is telling us is long. It is indeed exciting to think what the next decade will bring.
Sudhakaran Prabakaran and his colleagues Pranay Goel from IISER Pune and Leelavati Narlikar from the National Chemical Laboratory (NCL), Pune recently organized a workshop for local school and college teachers, titled ‘Introduction to Machine Learning focussed on application to Biology’.
The author would like to thank Lorena Magana Zertuche for providing the Spanish translation of the paragraph noted above.